
Når man skal navigere i den konstant udviklende teknologi for at udnytte potentialet i data, er det bydende nødvendigt at etablere et veldefineret dataflow og en veldefineret arkitektur. Microsoft Fabric forenkler processen i at konstruere både simple og yderst potente Data Lakehouse-løsninger. De primære mål med en Data Lakehouse-arkitektur omfatter:
- Etablering af en samlet dataplatform
- Sikring af skalerbarhed og fleksibilitet
- Forbedring af ydeevnen og omkostningseffektiviteten
- Eliminering af datasiloer
- Facilitering af forbedret beslutningstagning
- Forøgelse af driftseffektiviteten

Fig 1: Microsoft Fabric Best Practice Architecture
Væsentlige faser i et Data Lakehouse
I kernen af et Data Lakehouse finder man fire grundfaser: Ingest, Store, Prepare, og Serve – en klassisk ETL-proces. Disse faser fungerer som tandhjulene i en velsmurt maskine, der leder data jævnt gennem systemet fra kilderne til slutbrugerne.
Trin 1: Ingest af rådata fra kilder
Rådata fra forskellige kilder indlæses i første omgang i et "Landing" Lakehouse. Dette trin udføres effektivt af Data Factory Pipelines. OneLake leverer ”Shortcuts” til både eksterne og interne datakilder, og Spark-notebooks kan supplere ved at håndtere data fra blandt andet API'er.
Trin 2: Metadata-drevet klargøring og rens
Data gennemgår forberedelses-, rens- og valideringsprocesser, med en eller flere metadata-drevne notebooks, hvor PySpark er det foretrukne sprog. De rensede data gemmes derefter i Delta Lake-formatet i et "Base" Lakehouse, og resultatet er dataintegritet og -pålidelighed.
Trin 3: Forretningsmæssige transformationer med Spark SQL
Efter rens transformeres data til dimensioner og fact tabeller. Ligesom forberedelsesfasen udføres denne opgave af en eller flere notebooks - primært ved hjælp af Spark SQL. De transformerede data gemmes igen i Delta Lake-formatet, denne gang i et Lakehouse med navnet "Curated".
Trin 4: Levering af indsigt til slutbrugere
Det ultimative mål med enhver dataplatform er at levere værdifuld indsigt til alle slutbrugere af løsningen. I et Data Lakehouse opnås dette gennem en Power BI Semantic-model i Direct Lake. Alternativt tilbyder Fabric’s SQL Endpoint en mere traditionel metode til at gøre data tilgængelige for brugere på.
Orkestrering af et problemfrit dataflow
For at opretholde synkronisering og sikre et problemfrit dataflow, spiller Data Factory Pipelines en afgørende rolle som dirigent (eng. ”orchestrator”). De kontrollerer nemlig bevægelsen af data gennem forskellige faser og håndterer afhængigheder inden for disse faser.
Konklusion
Arkitekturen og dataflowet i et Data Lakehouse, drevet af Microsoft Fabric, præsenterer en kraftfuld og tilpasningsbar løsning til håndtering af data i stor skala. Ved at forstå de væsentlige komponenter og processer, kan organisationer frigøre deres datas fulde potentiale og fremme oplyst beslutningstagning og innovation.
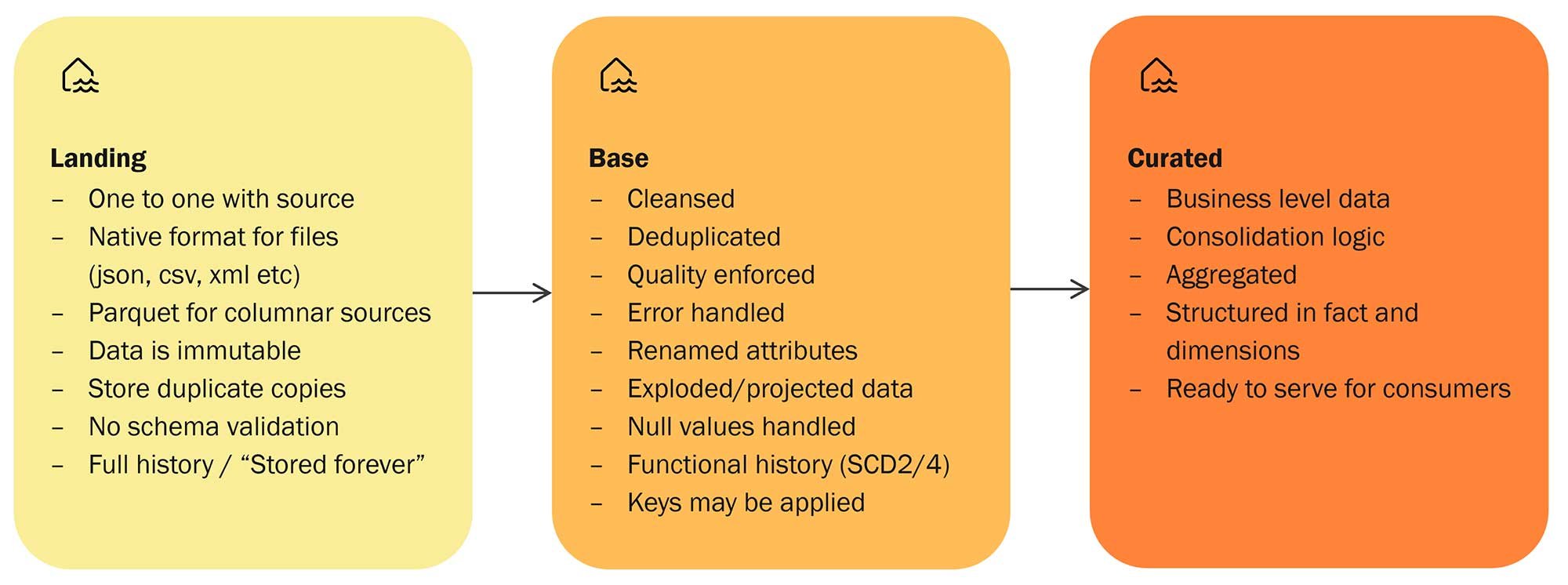
Fig 2: Layers in the Data Lakehouse
Løft arkitekturen med et framework
Et Best Practice Framework (BPF) fungerer som et robust værktøjssæt, der strømliner hurtig oprettelse og vedligeholdelse af Data Lakehouse-løsninger. Ved at anvende et framework kan de trivielle aspekter af Data Lakehouse-udvikling og opsætning af infrastruktur gøres automatisk, hvilket frigør udviklere til at fokusere på kerneforretningslogikken. Denne tilgang øger både produktiviteten og udviklingskvaliteten.
Opbygget efter principperne for ”konvention over konfiguration”, anvender frameworket skabeloner, standarder og omfattende dokumentation, der dækker alt fra opsætning og konfiguration af Data Lakehouse til dataudtræk og modellering. Best Practice Frameworket etablerer et robust grundlag for løbende udvikling.
De vigtigste fordele ved et Data Lakehouse Best Practice Framework:
- Lagdelt arkitektur: Forenkler den centrale definition, konfiguration og automatisering af dataflowet.
- Skalérbar: Muliggør problemfri integration af nye metoder og logik.
- Hurtigere Time-to-Market: Reducerer markant udviklingstiden ved at håndtere rutineopgaver og lade udviklere fokusere på værdiskabende aktiviteter for forretningen.
- Vedligeholdelse gennem metadata: Udnytter metadata til konfiguration og minimerer behovet for arbejdskrævende manuelle processer.
- Klar til DevOps: Out of the box integreres Best Practice Framewok problemfrit med Azure DevOps og dækker hele spektret fra initiel opsætning og udvikling til infrastruktur og implementering.
Frameworket introducerer følgende yderligere komponenter til arkitekturen:
- Azure SQL Database: Fungerer som et metadata-lager for dynamiske ingest-pipelines og automatiserer dataforberedelse, -rensning og -validering. Dette giver mulighed for at skabe generiske Pipelines og Spark notebooks.
- Azure Key Vault: Gemmer følsomme oplysninger på en sikker måde, f.eks. connectionsstrings og adgangskoder til kildesystemer.
- Azure DevOps: Fungerer som en samarbejdsplatform til opgavestyring, versionskontrol, dokumentation, CI/CD og implementering.
- Fabric Git Integration: Forbinder udviklingsarbejdsområdet til en feature Git branch i Azure DevOps, hvilket sikrer versionskontrol og samarbejde.
- Tabular Editor: Et udviklingsværktøj til at generere en eller flere semantiske data modeller oven på Data Lakehouse strukturen og metadata, der markant øger effektiviteten i modeloprettelsesarbejdet.

Fig 3: Framework components
Fundamentet for et Lakehouse Best Practice Framework hviler på arkitekturmæssige valg forankret i omfattende erfaring med udvikling af dataplatformsløsninger. Den inkorporerer dyb ekspertindsigt i den underliggende Microsoft Fabric-teknologistak. Et centralt designprincip understreger brugen af Fabric artefakter, hvor det er muligt, med anbefaling om kun at ty til andre Azure-tjenester, når en Fabric udgave ikke er tilgængelig.